| Search Indexed File Hierarchy The Search Module |
The search module of Search Indexed File Hierarchy is for searching Word DOCX files, HTML, XML and text files on hard disk, USB flash drive, CD-ROM, etc. (not for searching files on the web). It requires an index file previously created by the index module containing data regarding the contents of the searchable files.
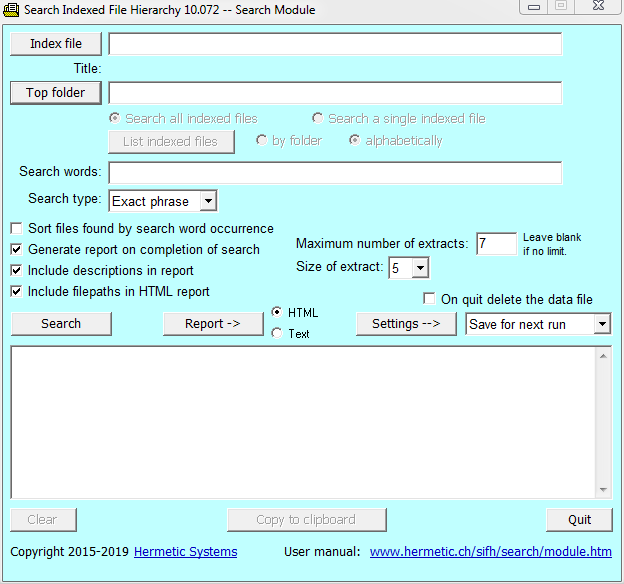
When first run the search module appears thus:
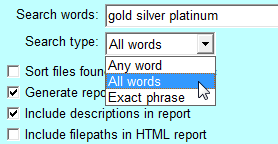 You can search for any word in the 'Search words' textbox, or all words, or the exact phrase (if more than one word). When searching for all words, common word such as the and and should not be included, because they will result in unwanted extracts. When searching for an exact phrase, the longer the phrase the quicker the search (since the more words required, the fewer the files containing all those words).
You can search for any word in the 'Search words' textbox, or all words, or the exact phrase (if more than one word). When searching for all words, common word such as the and and should not be included, because they will result in unwanted extracts. When searching for an exact phrase, the longer the phrase the quicker the search (since the more words required, the fewer the files containing all those words).
As stated previously, a word is any consecutive sequence of letters, numbers (that is, digits, 0-9) and optionally one or more hyphens, subject to the condition that the first charcter is a letter. Thus a word may not include an apostrophe or any other punctuation. Non-english characters such as ü and é are allowed in words. Searches are not case-sensitive (that is, no distinction is made between upper and lower case). There is no limit on the number of search words which can be given for a search.
Text in languages other than English is searchable. That is, the search words and words in the searchable text may contain non-English letters, such as as ä, é and ñ. Thus the software is compatible with text in German, Spanish and most European languages (but can't be used to find words containing an apostrophe, as occurs in French).
For an example of how to search a set of files see Example of Use.
What if the indexed files are edited?
Suppose you have created an index file for a set of files, then someone edits those files. Will this mean that the search module won't work properly and that those files have to be re-indexed? No. The index file does not take note of the exact positions of words in a file, so some minor editing will not affect the search results, except in the case that editing adds a word to a file which was not previously in that file and which is not in any other indexed file. In this case a search for that word will not return that file among the search results.
On the other hand, if editing removes all occurrences of a word from a file then a search on that word will not bring up the file in the search results (even though the word remains in the index) because the search module looks for that word in the file (in which it previously occurred), and if it does not find it then it will not display that file in the results.
The phrases displayed in the search results always accord with the current contents of a file, even if that file has been edited since the last time the index file was created.
Also, if an indexed file is deleted then this will not faze the search module. The deleted file will simply not show up in search results.
What if the indexed files are moved?
No problem. When the files to be searched are indexed only their paths relative to the original top folder are recorded. Thus the indexed files (in the original top folder and its lower folders) can be moved to a new location, that is, to a new top folder (on the same drive or a different drive). If you then specify this new folder as the top folder in the search module then the indexed files in their new location can be searched.
It may happen that you are using an index file for a set of files but wish to search just one of those files. In this case simply select the 'Search a single indexed file' option and specify the file in the usual way.

You can also search, in the same way, a single file which has not been indexed (yet). See Indexing and Searching a Single File.
A stem is a sequence of letters, etc., which may be the initial segment of some word. Stems are marked by a terminating asterisk, e.g., comput*. This software allows searching for multiple words by using stems as search words.
For example, if you search for dogm* the software will find all files containing any words which begin with that stem, e.g., dogma, dogmas, dogmatic, dogmatically, dogmatism, and dogmatists. As another example, if you search on fluorid* then the software will find all files which contain any of fluoridate, fluoridated, fluoridation and fluoride.
The asterisk can only be used at the end of a search word. You cannot search for, e.g., *like.
A stem is equivalent to the set of all words which occur in some file and which begin with that stem, so searching on that word is equivalent to doing an any-word search on all the words which begin with that stem. Thus a stem search must be an any-word search; stems may not be used in an all-words search or an exact-phrase search.
When a report is generated, if the search words include one or more stems then the actual words searched for will be displayed (labelled as 'Expanded [search words]'. If no words in any file match a search word (whether or not it is a stem) then that search word (or its expansion) will not appear in this list of actual words searched for. So, for example, if you search on bird gibbon dog* emu*, and bird, dog and dogs occur in some file (not necessarily the same file) but gibbon does not, nor does any word beginning with emu (such as emulate), then the list of expanded words will be bird, dog, dogs.
 The results of a search can be displayed either in a textbox within the software or as a web page in your default web browser (as mentioned in the example of use for this page). The display of results in the web page is preferable, since the search words are then displayed in boldface and there are links to the files found. The textbox option is provided in case there is some problem with displaying results in the default web browser.
The results of a search can be displayed either in a textbox within the software or as a web page in your default web browser (as mentioned in the example of use for this page). The display of results in the web page is preferable, since the search words are then displayed in boldface and there are links to the files found. The textbox option is provided in case there is some problem with displaying results in the default web browser.
If you have checked the 'Generate report' checkbox then the software will display the results automatically either by opening a textbox or by displaying a web page in your default web browser (you may have to switch to the browser manually). If you have not checked this checkbox then you can generate the report by clicking on the 'Report' button. The results can be preserved either by copying from the textbox to the clipboard (and from there to some text editor program such as Notepad) or by saving the web page to disk.
You can control whether the filepaths of the files found are displayed in the report by checking or unchecking the corresponding checkbox. If a file found is an HTML file then the description tag will be displayed in the report if the corresponding checkbox is checked.
As illustrated in the example of use above, you can also control the maximum number of extracts which will be displayed in the report and the size of these extracts (see more on both of these points below).
If the 'Sort files found by search word occurrence' is not checked then the files will be displayed in the order in which the index module found them when creating the index file, their physical order.
If this checkbox is checked then the program will take note of the relative frequencies of the search words found in the files. Files are then displayed in descending order of the sum of these frequencies for all search words. Thus files in which the relative frequencies of the search words are higher will be displayed earlier in the output.
"Relative frequency" here means: relative to the number of occurrences in the file of the word most-frequently occurring in the file, and is different from the absolute frequency of a word. The use of relative rather than absolute frequencies means that the size of the file in which a search word is found does not affect the position of that file in the search results.
If this checkbox is checked then the search will take a little longer.
There is no limit on the number of files which can be searched (other than that this is the number of files which were indexed) but there is a limit on the number of matches (files found containing one or more of the search words). At most 300 files can be returned in a search.
 When the report is generated (but not during the search itself) every occurrence of a search word is extracted together with several words before and after each search word, making a phrase called an extract. If the textbox next to 'Maximum number of extracts' is left blank then all these extracts will be displayed in the report. In an any-word search, or in a stem search, for each file in which at least one search word is found there could be over a hundred extracts. If you don't wish to see them all, but only, say, the first ten, then you can limit the output by specifying the maximum number of extracts to be displayed.
When the report is generated (but not during the search itself) every occurrence of a search word is extracted together with several words before and after each search word, making a phrase called an extract. If the textbox next to 'Maximum number of extracts' is left blank then all these extracts will be displayed in the report. In an any-word search, or in a stem search, for each file in which at least one search word is found there could be over a hundred extracts. If you don't wish to see them all, but only, say, the first ten, then you can limit the output by specifying the maximum number of extracts to be displayed.
The number of words before and after the occcurence of a search word is determined by the value selected for 'Size of extract'. For example, here are extracts (following a search for ferromagnetic) with this value set to 1, 3, 5, 7 and 9 respectively:
|
... models of ferromagnetic material. ... ... research concerns only models of ferromagnetic material. / The standard q-state ... ... material J < 0. This research concerns only models of ferromagnetic material. / The standard q-state Potts spin model is a ... ... of an antiferromagnetic material J < 0. This research concerns only models of ferromagnetic material. / The standard q-state Potts spin model is a spin model in which there ... ... J > 0, and for a model of an antiferromagnetic material J < 0. This research concerns only models of ferromagnetic material. / The standard q-state Potts spin model is a spin model in which there can be q different spin ... |
When you specify an index file, or when you load the settings after having saved them at the last run and you initiate asearch, the program looks for the data file associated with the index file. As explained in the section on the index module, a data file is created along with an index file, but need not be present when the search module is run. The search module looks for the associated data file in the same folder as the index file; if it is not found then the search module recreates the data file (in the same folder as the index file).
![]() If the 'On quit delete' checkbox is checked then the data file is deleted when the program ends. Not deleting it means that it will be available next time the program is run and does not have to be recreated by the search module (though this does not take long to do). The data file may be rather large if there are many searchable files and they contain many different words, so if searches are not performed on a daily basis then this file may be deleted to recover disk space.
If the 'On quit delete' checkbox is checked then the data file is deleted when the program ends. Not deleting it means that it will be available next time the program is run and does not have to be recreated by the search module (though this does not take long to do). The data file may be rather large if there are many searchable files and they contain many different words, so if searches are not performed on a daily basis then this file may be deleted to recover disk space.
| Search Indexed File Hierarchy | The Index Module |