| Hermetic Word Frequency Counter Advanced Version |
| Report Formats |
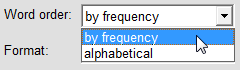
The result of a count can be displayed in various ways by selecting a word/phrase ordering and a report format from the 'Word order' and 'Format' drop-down menus.
|
 |
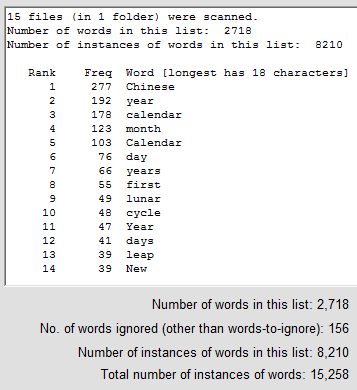
Using the default format (rank, frequency, word) produces reports such as the one shown below left (for absolute frequencies) and below right (for relative frequencies):
|

|
The relative frequency of a word or phrase is the frequency count of that word or phrase divided by the total number of occurrences of all words or phrases in the list, expressed as a percentage. In this example, the world cycle occurs 48 times in all 15 files, and there are 8,210 occurrences of all counted words in these files, so the relative frequency of cycle in these files (among the words which were counted) is 48*100/8210 = 0.58 percent (to two decimal places).
The format selection affects both how results are displayed in the program and how they are written to an output file. Words and phrases found may be displayed in reverse alphabetical order as well as alphabetical and by frequency. The 'rank' and 'frequency' values may each be included in, or excluded from, the displayed results. If the output file consists only of words, with no rank or frequency count values, then you can get these either as a list (one word per line) or as comma-separated.
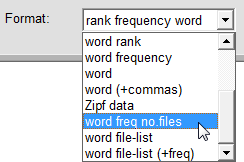
the Advanced Version has four possibilities for reporting the results of a count which are not available in the basic version. One of these is Zipf data, which produces logarithms of the rank and frequency values. For some possibile uses see the page about Zipf's Law.
The other three report formats (in the list below 'Zipf data') are possible only when the source of the text to be scanned is a folder. Unlike the earlier ones these formats provide file names and other information about the files in which the words/phrases are found.
| Selection option | For each word/phrase this displays | |
| word freq no.files | its frequency and the number of files in which it occurs | |
| word file-list | a list of the files in which it occurs | |
| word file-list (+freq) | its frequency plus a list of the files in which it occurs |
Three examples are given below.
First Example
Suppose we have all the HTML files making up the section on this website on Spin Models in a folder \spin_models. In the software we set the folder to this, then we can count the number of occurrences of certain phrases in these HTML files. These phrases can be placed in a count-only words/phrases file, or, if there are just a few, we can specify them in the 'Settings' window as follows (for example):

Phrases must be separated by a comma plus a space (not just a comma).
If we check the boxes in the 'Settings' window to allow hyphens and numerals, set the word order to alphabetical, select 'rank frequency word' for the display order, then click on the 'Count word/phrase frequencies' button, the results will be returned in about 10 seconds, as follows:
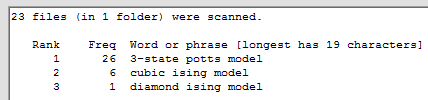
If we now select 'word freq no.files' for the display order we get:
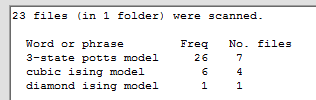
Selecting 'word file-list' gives us the result at left and selecting 'word file-list (+freq)' gives the result at right:

|

|
Second Example
As our second example, suppose we have a number of HTML files which contain the names of many chemical compounds (e.g., the 57 files composing the online edition of the book TIHKAL) and that there are seven compounds we are interested in, namely:
N,N-dioctyltryptamine diisopropylethylamine 1-acetylindole-3-acetone 3,4,5-trimethoxybenzaldehyde 5-methoxy-3-(2-nitropropenyl)indole 3-methoxy-4,5-methylenedioxybenzaldehyde 4-acetoxyindol-3-yl-N,N-dibutylglyoxylamide |
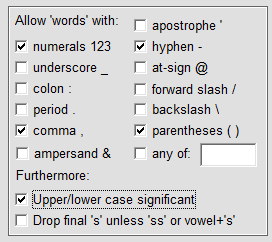 Assuming that we have all 57 HTML files on our local PC we select 'Folder' and select the folder containing these files. Then assuming that the names of the compounds are in a text file as above we specify (in the 'Settings' window) this file as the count-only words file.
Assuming that we have all 57 HTML files on our local PC we select 'Folder' and select the folder containing these files. Then assuming that the names of the compounds are in a text file as above we specify (in the 'Settings' window) this file as the count-only words file.

When the software loads this file it will automatically add the characters occurring in the names to the set of allowable characters as shown at right. ('Upper/lower case' etc. are not changed by this.)
Note that if the option for ignoring words which occur less than a certain number of times is checked then there is no need to uncheck it since, as noted above, the 'Ignore words' settings have no effect when there are count-only words, as there are in this example. After looking over the other parameter settings we can now run the software with word order set to 'by frequency' and display option set to 'word freq no. files' to obtain this result:
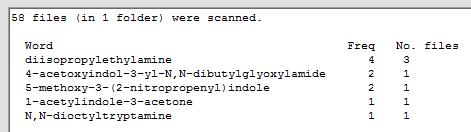
If we wish to know in which files these names occur then changing the display option to 'word file-list' (and the word order to 'alphabetical') gives us immediately (without having to re-scan the files) the following:

 If we want to know exactly how often diisopropylethylamine occurs in each of the three files then we can select the display format 'word file-list (+freq)' to obtain:
If we want to know exactly how often diisopropylethylamine occurs in each of the three files then we can select the display format 'word file-list (+freq)' to obtain:
Although there is no limit on the number of files which can be scanned, the number of files which can appear in a list of files in which a particular word occurs is limited to 10,000, and the program stops counting the number of occurrences of a word in a file when it reaches 99,999 (limits which are anyway unlikely to be reached).
Third Example
This software can be used to do things besides counting words and phrases. For example, suppose you have several text files containing words sorted alphabetically, but with many words in common, and you want a single file containing all those words, sorted alphabetically, with each word occurring once only. This software will scan all those files and (with the report format set to 'word') write out a file containing all the words in alphabetical order with each word occurring just once.As another example, suppose you have a set of text files (such as HTML files) which are the chapters of a book. In the same way as stated in the previous paragraph (with the report format set to 'word') you can get an output file containing all words occurring in the book (optionally, with common words ignored). Immediately rename this file so that the software does not overwrite it (and delete the first line). Specify this file as the count-only words file and run the software on the chapters of the book, with format set to 'word file-list (+freq)'. You will then get a report such as:
abandon
1 C:\book\chap17.html
1 C:\book\chap13.html
2 C:\book\chap19.html
1 C:\book\chap32.html
abandoned
1 C:\book\chap02.html
1 C:\book\chap17.html
1 C:\book\chap10.html
2 C:\book\chap22.html
1 C:\book\chap32.html
1 C:\book\chap01.html
1 C:\book\chap33.html
| abandoning
1 C:\book\intro.html
abandonment
2 C:\book\chap11.html
2 C:\book\chap33.html
abbot
8 C:\book\chap35.html
1 C:\book\chap30.html
3 C:\book\chap32.html
abeyance
... |
which tells you, for each word, which chapters it occurs in and how many times in each chapter.
| Introduction | User Manual: Contents |
| Hermetic Systems Home Page | |