| | Hermetic Word (and Phrase) Frequency Counter
Advanced Version |  |
A Customizable Multiple-File Word and Phrase Counting Program for Windows |
This software runs on any version of Windows. It is fully-functional and not time-limited.
Donate via Stripe to download this software.
Hermetic Word Frequency Counter Advanced Version scans one or many MS Word DOCX files or text or text-like files — including HTML and XML files encoded via ANSI or UTF-8 — and counts the number of occurrences of the different words in all files together (optionally ignoring common words such as the and this). It is thus also a multiple-file word-search program. It is possible to specify exactly what counts as a word (e.g., words with or without hyphens or numerals). The words and phrases found can be listed alphabetically or by frequency, with rank and frequency count displayed for each.
This software comes in two versions: Hermetic Word Frequency Counter (WFC) and Hermetic Word Frequency Counter Advanced Version (WFCA). These are two separate programs. The main difference is that WFC counts words only in single DOCX, text and text-like files (including HTML and XML files), whereas WFCA counts words and phrases in multiple files (in multiple folders) in a single operation. If you need to count words in only one file at a time then WFC is what you need. (Click on this link for the WFC page.) If you have many files or wish to count phrases or need more options and functionality for words and phrases) then you need WFCA (so read on).
Theoretically there is no limit on the size of an input file or the number of words in it, but in practice (due to processing time needed) there is a limit of about 10 Mb on text files (and text-like files such as XML and HTML files). There is also a limit of about 10 Mb on the amount of text in an MS Word DOCX file (though a DOCX file can be larger than this if it contains many images). For a DOCX file, only words in the body of the document are counted, not words in footnotes or endnotes.
The Advanced Version does everything that the basic version does, including support for UTF-8 encoded text. The section below details the additional functionality of the Advanced Version, mainly, the ability to count words in multiple files, the ability to count phrases as well as words, and the ability to count occurrences of a word or a phrase which matches a specified pattern (so it is also a multiple-file search program). Thus the user manual for the basic version should be read in conjunction with this page.
This software counts words and phrases in MS Word DOCX files (but not Word DOC files) and in text and text-like files (including HTML and XML files). It does not act directly on binary files (other than DOCX files) such as PDF files; such files can be processed if they can be converted to DOCX files or to text files (see Scannable Files in the user manual for the basic version).
To open a single file to count words or phrases, select the Single File option and click on the Single File button. To count words or phrases in multiple files in a particular folder, select the Folder option and click on the Folder button. After setting the operation parameters click on the appropriate Count button. Below is a screenshot showing the results of counting words in all .htm files in a folder and its subfolders (case not significant):
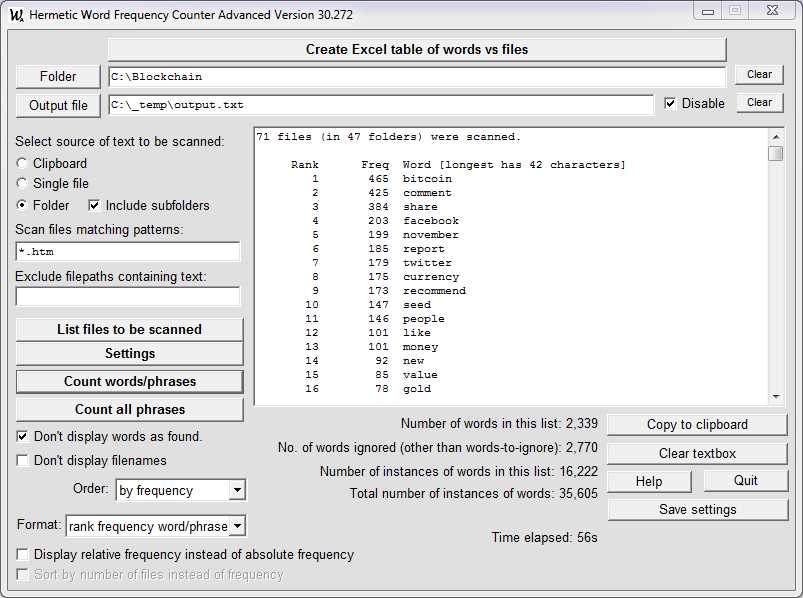
If the "Disable" box (on the same line as "Output file") is checked then output is to the text box only, not to a file.
Click here for a screenshot showing the output when relative frequencies (instead of absolute frequencies) are calculated.
Here is a screenshot showing the result of counting all phrases of from 4 to 8 words in a DOCX file of size 21.46 Kb containing 13.70 of actual text:
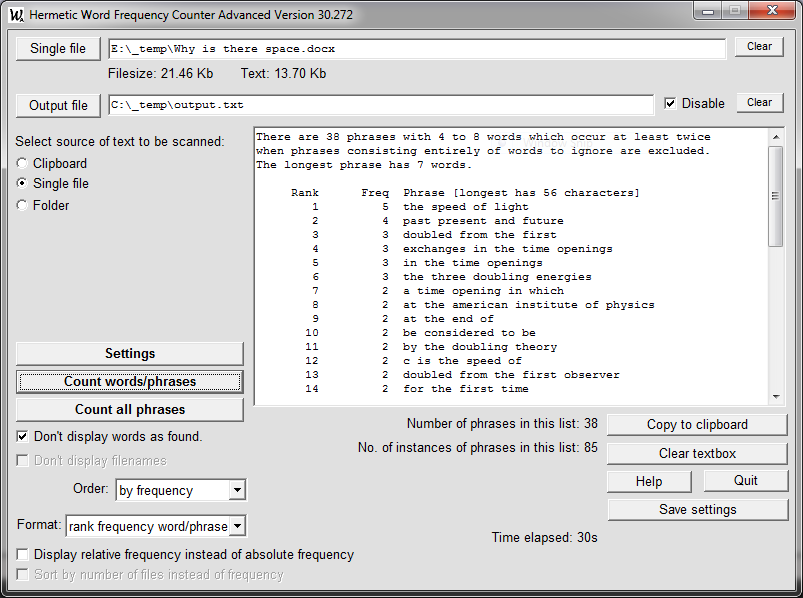
"Filesize" is the size of the DOCX file; "Text" is the size of the text within that file. With a large DOCX file the former may be smaller than the latter because the text within a DOCX file is compressed.
This software has many different uses. One example is for searching for words and phrases in news stories. You can download multiple pages from the web then search through them for such terms as “economic recovery”, “chinese stocks”, “air traffic controller strike” and “IMF payment”. Searches can return the names of the files in which the target phrases occur, as explained at Report Formats (see also Sorting Documents by the Number of Occurrences of a Word or Phrase). There are, of course, many other possible uses for this software.
Differences from the Basic Version
The following are some (but not all) features of the Advanced Version (WFCA) which are not present in the basic version (WFC):
The ability to:
- count not just all words in a file but also all phrases (within bounds of phrase length).
- scan not just one file but all files in a folder, and optionally in all subfolders of that folder, and to return a single report on the frequencies of words and phrases in all files scanned.
- specify not only a list of words to be ignored (such as common words in a natural language) but also specify a list of words and phrases which are to be counted (or searched for).
- count words or phrases matching a given pattern.
- ignore words matching a given pattern.
- display relative frequency of occurrence as well as absolute frequency.
- display, for each word or phrase found when scanning multiple files, the files in which it occurs, and how many times.
- order words or phrases according to the number of files in a set of files in which those words or phrases occur.
- include or exclude files of certain types.
- generate an Excel-readable file containing a table of frequencies of words and phrases vs the files in which they occur.
And, new in Version 26.07, the ability to filter found phrases so as to display only phrases containing specified words.
Most users will need just a few of these abilities, so only the relevant parts of the user manual need be consulted.
The 'Settings' Panel
Here is what the 'Settings' panel looks like in the Advanced Version:
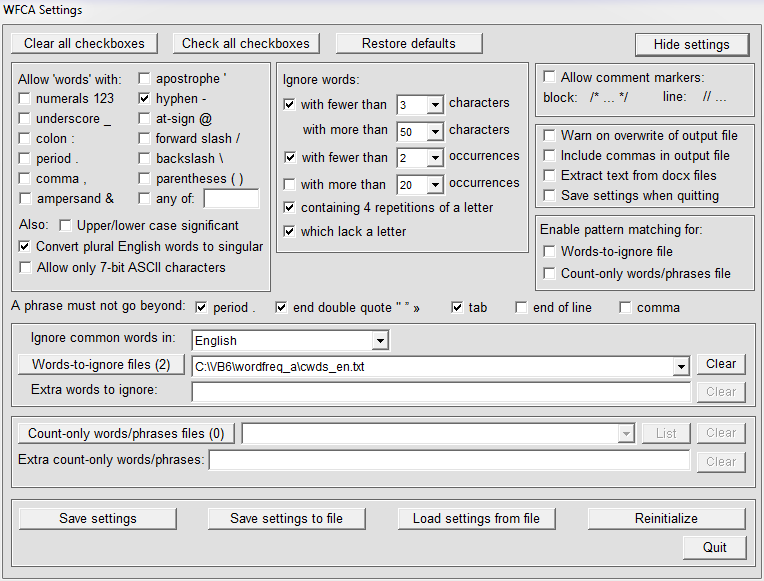
The Convert plural English words to singular checkbox and the Ignore words with fewer than (or more than) N occurrences checkboxes are applicable only when counting words, not when counting phrases.
The default for Phrase must not go beyond ... is everything except 'comma' and 'end of line'. If your document consists of phrases separated by commas then you should check the box for 'comma'. Such text should not be mixed with text where an end-of-line, period or double quote terminates a phrase.
User Manual for Hermetic Word Frequency Counter Advanced Version
As stated above, the Advanced Version does everything that the basic version does, so the following sections of the user manual for the basic version apply also to the Advanced Version.
{kind=link}