| Hermetic Word Frequency Counter Advanced Version |
| Counting and Searching for Words and Phrases which Match Patterns |
This software allows you to count or search for words and phrases in a file (or in multiple files) which match specified patterns. The patterns are specified either by manual entry in the 'Extra count-only words/phrases' textbox or by including them in a count-only words/phrases file (as shown here).
Words which you wish to ignore (also called 'stop words' in some quarters) may also be specified using patterns. Words-to-ignore may be included in a words-to-ignore file or entered manually in the 'Extra words to ignore' textbox in the 'Settings' window.
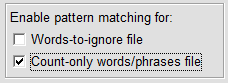 If you wish to include patterns in a count-only-words/phrases file or a words-to-ignore file, then you have to check the relevant checkboxes at the 'Settings' window. This is because including patterns in these files reduces the speed of the program, especially if the files are large. When counting/searching is to be done without pattern matching, then both these checkboxes should be unchecked.
If you wish to include patterns in a count-only-words/phrases file or a words-to-ignore file, then you have to check the relevant checkboxes at the 'Settings' window. This is because including patterns in these files reduces the speed of the program, especially if the files are large. When counting/searching is to be done without pattern matching, then both these checkboxes should be unchecked.
It is possible, however to use patterns among the extra count-only words/phrases and the extra words-to-ignore, whether or not these checkboxes are checked. Their state affects only the operation of the program when count-only words/phrases and words-to-ignore are to be included in files.
There are two ways to specify a pattern:
|
Simple Patterns
 Those old enough to remember using the MS DOS operating system will recall that a set of files could be specified by using * and ? in a filename, e.g., *.txt. A similar pattern-matching convention is implemented in this software for word and phrase counting, the only difference being that ~ rather than * is used to mean any string of characters .
Those old enough to remember using the MS DOS operating system will recall that a set of files could be specified by using * and ? in a filename, e.g., *.txt. A similar pattern-matching convention is implemented in this software for word and phrase counting, the only difference being that ~ rather than * is used to mean any string of characters .
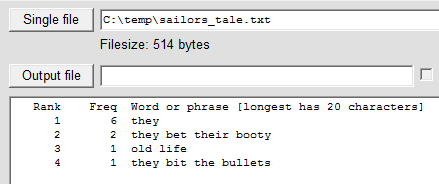 So a~ means any word beginning with a, and ~th means any word ending in th.
? means any single character, so b?t matches bat, bet, bit and but, but it does not match bt or bite. b~t? matches bite, boats, booty and behemoth, but not baton. So if you specify they b?t ~ b~t? as a pattern for phrases to be counted then the count will include all occurrences of they bet their booty, they bit the bullets and so on, but not they bought four bats.
So a~ means any word beginning with a, and ~th means any word ending in th.
? means any single character, so b?t matches bat, bet, bit and but, but it does not match bt or bite. b~t? matches bite, boats, booty and behemoth, but not baton. So if you specify they b?t ~ b~t? as a pattern for phrases to be counted then the count will include all occurrences of they bet their booty, they bit the bullets and so on, but not they bought four bats.
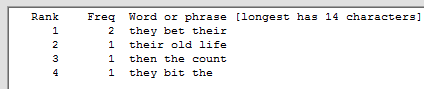 ~ matches an empty string only if combined with other characters, as in a~ and a~t. When used alone it means any non-empty string, as in a ~ person. ? must always match some character. So t~ ??? ~ would count all sequences of three words whose first word begins with t and whose second word has exactly three letters.
~ matches an empty string only if combined with other characters, as in a~ and a~t. When used alone it means any non-empty string, as in a ~ person. ? must always match some character. So t~ ??? ~ would count all sequences of three words whose first word begins with t and whose second word has exactly three letters.
Multiple simple patterns for words/phrases to be counted may be included in the Extra count-only words/phrases textbox in the WFCA Settings window. They may not be included in a count-only words/phrases file (regular expressions should be used instead).
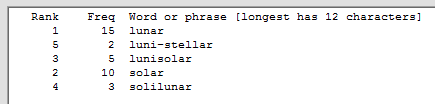
Counting words in this English web page matching either of the simple patterns sol~ and lun~, without regard to case, produces the result shown below left. Case is important when counting words in German text. Counting words in this German web page matching any of the simple patterns sol~, Sol~, lun~, Lun~, with case significant, produces the result shown below right.
|
|
|
|

|
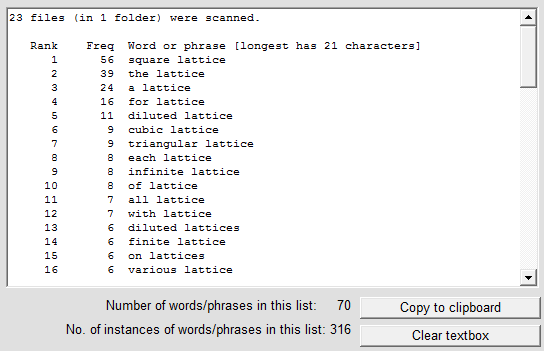 Pattern-matching can also be used when counting words in multiple files. For example, suppose we wish to find all pairs of words, of which the second is either "lattice" or "lattices", which occur in the 23 HTML files composing the online version of the author's M.Phil. thesis. After specifying the folder which contains these files, we can use the pattern ~ lattice~ to obtain the result at right (click for full image).
Pattern-matching can also be used when counting words in multiple files. For example, suppose we wish to find all pairs of words, of which the second is either "lattice" or "lattices", which occur in the 23 HTML files composing the online version of the author's M.Phil. thesis. After specifying the folder which contains these files, we can use the pattern ~ lattice~ to obtain the result at right (click for full image).
Regular Expressions as Patterns
Regular expressions are rather more complex than the simple patterns decribed above, and are not for everyone. The rest of this page assumes that you have a basic familiarity with regular expressions, and that you know, e.g., that '.' represents a letter or character and that '*' means 'any number (possibly zero) of the previous character or subexpression'.Regular expressions (unlike simple patterns) can be used both in the Extra count-only words/phrases textbox (at the WFCA Settings window) and in a count-only words/phrases file.
Patterns specified via regular expressions are checked for validity and an error message is displayed if one is found to be invalid.
To distinguish a regexp from a simple pattern, a regexp must be enclosed within angle brackets: <...>. Thus a regexp (as used with this program) cannot itself contain an angle bracket.
Since this software was designed for counting words and phrases (mainly in natural language text) there are some restrictions on the use of regular expressions. When creating a count-only word or phrase using regexp's each expression (enclosed in angle brackets) should be intended to match a single word in the text, not a phrase. Thus a regexp cannot contain a space.
Furthermore, any occurrence of '.', '^' or '$' must either occur within square brackets (e.g., '[.^$]') or be escaped (e.g., '\$').
The reason for excluding an unescaped and not-within-square-brackets '.' from regexp's is that '.' can match a space, so that, e.g., '<ABC.XYZ>' would match 'ABC XYZ', and thus the expression would match two words in the text, which contradicts the requirement (with this software) that a regexp (enclosed in angle brackets) must match a single word.
Instead of '.' one can use '[\S]', since '\S' means 'any non-white-space character', i.e., any character which is not a space, tab, new line or form feed. So although '.*' cannot be used to match any sequence of characters, you can use '[\S]*'.
As an example of a non-trivial regexp, suppose you wish to count occurrences of email addresses in a file (or set of files). There are various regular expressions intended to match valid email addresses. The following regular expression will match almost all email addresses in actual use:
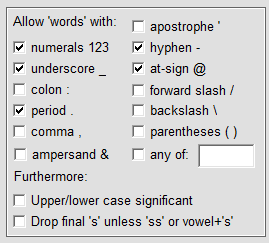 To obtain email addresses you must allow 'words' with @-signs, numerals, underscores, hyphens and periods (as shown at right).
To obtain email addresses you must allow 'words' with @-signs, numerals, underscores, hyphens and periods (as shown at right).
Copy and paste the above regexp (enclosed in angle brackets) into the Extra count-only words/phrases textbox as shown below.
You can then apply the program to a file containing, e.g., messages sent to a mailing list, to obtain a result such as shown below (with parts of the email addresses redacted).

It was stated above that a regexp used with this software cannot contain an angle bracket. But what if one has a file in which there are email addresses of the form TO:<abc@def.com>? One cannot use the following as a regexp because if it is enclosed in angle brackets then an angle bracket would occur within angle brackets, which is not permitted.
There is an easy solution: Use the simple pattern TO:~ (no space after the colon). If there are email addresses of the form TO: <abc@def.com> then the simple pattern TO: ~ (space after the colon) will get these. If a file has email addresses in both forms then TO:~, TO: ~ will get both kinds. (The same applies to "FROM:" email addresses.)
Simple patterns may be mixed with regular expression patterns. For example, if you are counting phrases in this article, and you specify
 |
as the pattern for the phrase to be counted, then (with upper/lower case significant) the result is as shown at right. Of course, the same result could be obtained by using the simple pattern Jul~ Ca~r ~ ??, but not all phrase patterns using regular expressions can be written using the simple pattern matching method.
Note that pattern matching using regular expressions, as described above, is subject to the restrictions on admissible characters (and admissible positions in words of certain characters) which are stated in the section What is a Word?. Thus, for example, <\ba[\S]*> will count all occurrences of anthropod (and all occurrences of words beginning with 'a') but <\b\(a[\S]*\)> will not count occurrences of (anthropod) (assuming that parentheses are allowed within words) because the program does not allow parentheses at the start or end of a word.
| Introduction | User Manual: Contents |
| Hermetic Systems Home Page | |