Phrase Frequency Counter Advanced |
|
Phrase Frequency Counter Advanced |
|
This software runs on any version of Windows. It is fully-functional and not time-limited.
Donate via Stripe to download this software.
Phrase Frequency Counter Advanced scans MS Word DOCX files, text and text-like files — including HTML and XML files encoded via ANSI or UTF-8 — and counts the number of occurrences of the different phrases. It is also a multiple-file phrase-search program. It is possible to specify exactly what counts as a word (e.g., words with or without hyphens or numerals). The phrases found can be listed alphabetically or by frequency, with rank and frequency displayed for each. It is possible to search within the set of found phrases.
Theoretically there is no limit on the size of an input file, but in practice (due to processing time needed) there is a limit of about 10 Mb on text files (and text-like files such as XML and HTML files). There is also a limit of about 10 Mb on the amount of text in an MS Word DOCX file, though a DOCX file can be much larger than this if it contains many images.
A letter is an element of an alphabet in some language. A word is a sequence of letters and optionally some non-letters such as digits and the hyphen, as in little‑used. (What counts as a word, for this software, is discussed in more detail at What is a Word?) A phrase is a sequence of words separated by spaces and non-letters. There is a setting available to specify what character(s) a phrase must not go beyond. You can specify what characters are admissible in words via the Settings window:
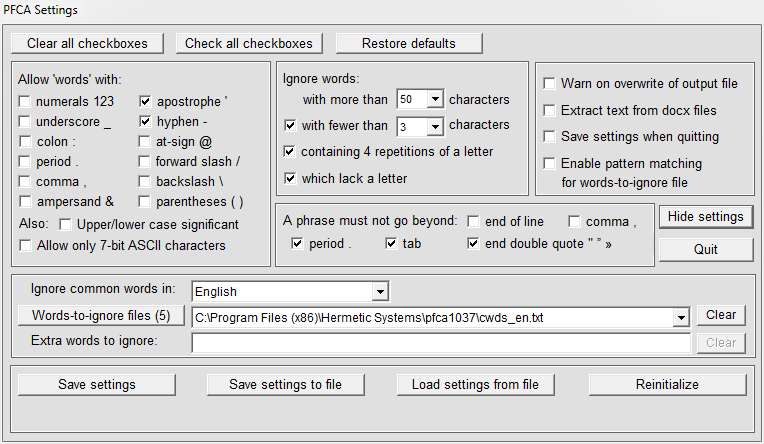
The default for Phrase must not go beyond ... is everything except 'comma' and 'end of line'. If your document consists of phrases separated by commas then you should check the box for 'comma'. Such text should not be mixed with text where an end-of-line, period or double quote terminates a phrase.
The number of phrases in a piece of text is approximately the square of the number of words in that text. Thus text longer than 50 words contains thousands of phrases. So when counting phrases it is necessary to limit the length of a phrase. It may also be helpful to exclude phrases which are of no interest, in particular phrases consisting entirely of words which are of no interest. In this software, words which are of no interest are called words to ignore (or in the terminology of linguists, stop words), such as the, that, he, on, about, etc. This software comes with words-to-ignore files for several languages. So when the program starts up it may ask whether you wish to load the words-to-ignore file for English (or some other language). If not, you can load such a file via the Settings panel. You can also specify extra words to ignore with particular documents.
To open a single file to count phrases, select the Single File option and click on the Single file button.
Having specified the file containing phrases to be counted you need to decide how long the phrases should be. Do this via specifying the minimum and maximum number of words in a phrase in the Settings panel. Most phrases will occur only once, so if you're not interested in every phrase then specify the minimum number of occurrences. Now click on the Count phrases button to get the phrases, as in the example below:
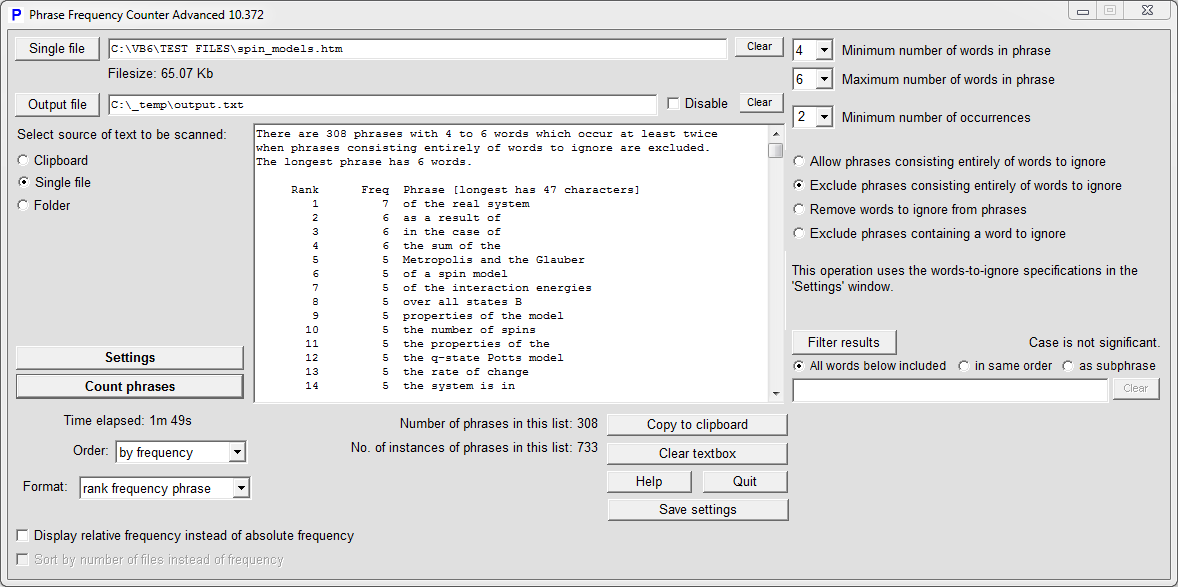
You can now order the phrases either alphabetically or by frequency, and display as frequency+phrase and in other ways..
If we now select Remove words to ignore from phrases and recount phrases then we obtain:

which may be more informative. You may have to widen the whole window (by dragging its right margin to the right) to get every phrase on one line.
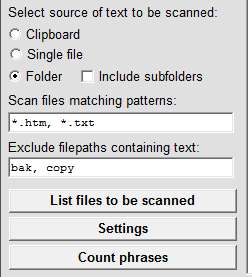 The procedure for counting phrases in multiple files in a folder is similar. First select the Folder option and then click on the Folder button to specify the folder containing the files (and optionally the files in subfolders, if any) to be scanned.
The procedure for counting phrases in multiple files in a folder is similar. First select the Folder option and then click on the Folder button to specify the folder containing the files (and optionally the files in subfolders, if any) to be scanned.
You can specify which files to be included in the scan and which (if any) should be excluded.
You can list the files (and possibly subfolders) to be included before proceeding to count the phrases.
As before, you can now order the phrases either alphabetically or by frequency.